
11月11日的资金流向数据方面,主力资金净流出2698.15万元,占总成交额9.17%,游资资金净流出490.47万元,占总成交额1.67%,散户资金净流入3188.62万元,占总成交额10.84%。
11月11日的资金流向数据方面,主力资金净流出2443.31万元,占总成交额13.63%,游资资金净流出562.3万元,占总成交额3.14%,散户资金净流入3005.61万元,占总成交额16.77%。
点击收听本新闻听新闻近期,加州大学研究人员和英伟达在共同发表的新论文中提出“NaVILA模型”,NaVILA的核心创新在于,不需要预先的地图,机器人只需“听懂”人类的自然语言指令,结合实时的视觉图像和激光雷达信息,就可以自主导航到指定位置。
想象一下这样的场景:你早上醒来,家中的服务机器人正在等候你的指令。
你轻轻说道,“去厨房,拿瓶水过来。” 不到一分钟,机器人小心翼翼地穿过客厅,绕开沙发、宠物和玩具,稳稳地站在冰箱前,打开冰箱门,取出一瓶矿泉水,然后轻轻送到你手中。
这一幕曾经只出现在科幻电影中,而现在,得益于NaVILA模型的出现,这正在变成现实。
NaVILA不仅摆脱了对地图的依赖,还进一步将导航技术从轮式扩展到了腿式机器人,使得机器人在更多复杂场景中,具备跨越障碍和自适应路径规划的能力。
在论文中,加州大学研究人员使用宇树Go2机器狗和G1人形机器人进行了实测,根据团队统计的实测结论,在家庭、户外和工作区等真实环境中,NaVILA的导航成功率高达88%,在复杂任务中的成功率也达到了75%。
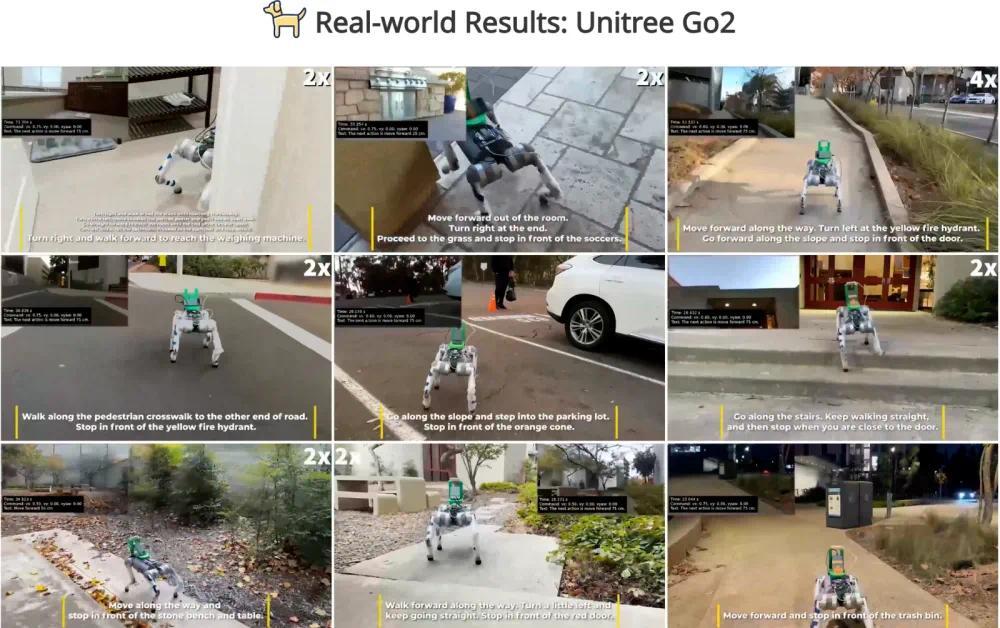

(使用NaVILA实测机器狗和机器人听指令行动)
这项研究给机器人导航范式带来革新,让机器人的路径规划从“地图依赖”走向“实时感知”。那么,NaVILA采用了什么样的技术原理?它会给机器人带来哪些新的能力?

提出“中间指令机制”,
机器人可以自行拆解指令
在传统的VLN(视觉语言导航系统)中,机器人需要依靠激光雷达(LiDAR)和SLAM算法绘制和维护静态地图。无论是家用扫地机器人还是仓储中的AGV小车,这类机器人只能在预先已知的环境中运行。
一旦面临动态环境,比如家中宠物走动、仓库货架更替这类场景,静态地图的效用大幅削弱,机器人必须频繁重绘地图,而这会增加系统成本和计算负担。
但NaVILA不一样,它可以实现“无图导航”。
这主要是通过两套机制来实现的,一种是高层控制器(视觉-语言-行动(VLA)模型),一种是低层控制器。
在高层控制器层面,NaVILA通过视觉-语言-行动(VLA)模型来实现“无图导航”,即通过视觉图像、激光雷达和自然语言的多模态输入,让机器人实时感知环境中的路径、障碍物和动态目标。
这套视觉-语言-行动(VLA)模型分三个工作流:
● 输入阶段:机器人会接收自然语言的指令和摄像头的图像,将人类的语言信息和摄像头看到的画面结合起来,识别出路径中的关键目标,比如前方的墙、左边的障碍物、右边的楼梯等;
● 中间指令生成:生成一份“路径规划表”,VLA会生成一系列中间的高层动作指令,这些指令可能是“前进50厘米”、“向左转90度”、“迈过障碍物”等,类似于“简化的路径操作说明书”;
● 高频控制器调用,它的任务是实时控制每一个关节的运动。
在这套工作流之中,NaVILA的最大亮点是提出了一种“中间指令机制”,这种机制让机器人不需要“死记硬背”每个关节的动作,而是像人类一样,听懂高层的指令后,再自行拆解为具体的行动。
“中间指令机制”可以让机器人听懂用户日常式的交流语言,不同类型的机器人能够根据自己的“身体结构”去实现动作。
通俗来说,传统的导航机器人就像一个“机械的搬运工”,每次你要告诉它“左脚先抬,右脚再抬,前进5厘米”,这种控制方式非常繁琐。
而NaVILA的VLA模型更像一名懂事的助手,你只需要说“向前走50厘米”,它就会自己拆解成“抬左腿、抬右腿、重心前移”等小动作。
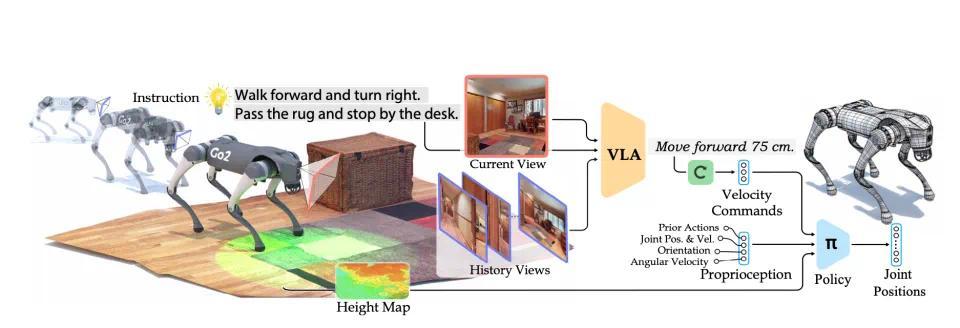
(NaVILA是一个两级框架,将高级视觉语言理解与低级运动控制相结合)
高层控制器(VLA)为机器人生成了路径规划表,但“路径规划表”只能告诉机器人往哪里走,却不会告诉它怎么走。
这时就需要一个“低层控制器”来接手,控制机器人具体的关节动作。
假设你让一个小孩学习走路,如果你只告诉他“去客厅”,他会问你“怎么去?怎么迈步?先迈左脚还是右脚?” 在这个场景中,VLA就像家长的语音指令(“去客厅”),而低层控制器就是小孩自己的“肢体控制系统”,它需要根据“去客厅”的目标,控制每只脚的迈出步长、落地角度和重心平衡,以确保自己不摔倒。
NaVILA的低层控制器使用了一种PPO强化学习算法,通过在NVIDIA的Isaac Sim虚拟仿真平台中训练机器人,让机器人学会如何站稳和行走,它的强化学习系统会反复训练机器人在草地、台阶、楼梯、石子地等不同的地形中行走,并且要确保机器人在这些不规则的环境中不摔倒。不是靠算,而是靠模拟。
在高层控制器和底层控制器的耦合之下,NaVILA有助于将机器人变得更通用。

NaVILA为机器人带来了哪些新可能?
NaVILA将导航技术从轮式机器人延展到了腿式机器人。
传统的VLN基本都是为轮式机器人而设计的,轮式机器人通常在平坦的地面工作,它的导航指令通常是“前进X米,左转X度”。
这些命令适配轮式机器人很方便,但腿式机器人需要更精细的控制,因为它们通常要面临更复杂的地形和障碍物。
而NaVILA的“中间指令”更亲民,用户只需说“去厨房,帮我拿瓶水”,机器人便可理解这段语义,规划路径,执行任务,而不必说出“前进2米,左转90度”之类的指令。
此外,使用NaVILA的指令还包含更具体的动作信息,如“迈出一小步”、“抬脚越过障碍物”等。
这使得NaVILA能够将高层次的路径规划与底层的腿式运动解耦,让同一套VLA控制逻辑可以适配不同的机器人平台。
从这个角度来看,NaVILA可以用来控制不同形态的机器人,比如四足机器人和人形机器人。
在论文公布的测试视频中,工作人员使用NaVILA通过语言顺利命令宇树Go2机器狗和G1人形机器人运动。
从实测来看,NaVILA无图导航能力也有助于扩大适应人类环境的足式机器人的实际使用场景。

(宇树Go2机器狗接受行动指令:向左转一点,朝着肖像海报走,你会看到一扇敞开的门)

(宇数G1人形机器人接受行动指令:立即左转并直行,踩上垫子继续前进,直到接近垃圾桶时停下来)
为什么这么说?因为在传统的VLN系统中,没有地图,机器人就移动不了,一旦环境发生变化,机器人就很难应付。
所以,NaVILA虽然没有让机器人“长腿”,但它让“长腿的机器人更聪明”。
过去,足式机器人虽然有“腿”,但每次驱动它们都需要同时控制膝关节、髋关节、脚踝等多个关节。
如果用传统的控制逻辑去设计,需要为每个关节写代码,还要不断调整,成本高且难度大,NaVILA则降低了足式机器人的运作成本。
同时,这也扩大了机器人的使用场景。
比如,在家庭场景,过去的扫地机器人只能在单一的房间中打转,因为它跨不过几厘米高的门槛。而足式机器人却能像人一样,一步跨过门槛,走进厨房,为你取一瓶水。当你说“去厨房拿瓶水”,它不仅听得懂,还能在家中绕过宠物、躲开玩具,灵活自如地完成任务。
在搜索救援和灾后救援场景中,足式机器人在地震废墟中,碎石、瓦砾、钢筋等不规则的地面行走,它可以跨越障碍、爬过瓦砾、深入废墟深处,帮助搜救人员寻找幸存者。NaVILA的“无地图导航”能力还意味着,即使搜救环境不断变化,机器人也能根据实时的路径感知,自动调整路线。

结 语
NaVILA帮助机器人从对死板的地图或复杂的传感器的依赖中解脱出来,机器人可以像人类一样,通过语言与视觉的结合在复杂的环境中找到自己的路。
尤其是对于四足式机器人,NaVILA给它们带来了更大的自由度实盘杠杆平台,使得足式机器人能够灵活地应对不规则的地形和障碍。